

Как получить мини-исследование с помощью нейросетевой модели

Объем доступной информации растет лавинообразно и сориентироваться в ней становится возможным только с помощью инструментов для поиска. Трансформацию и эволюцию цифровых навигаторов рассматривает в колонке для IQ Media главный эксперт Центра стратегической аналитики и больших данных ИСИЭЗ НИУ ВШЭ Софья Приворотская.
Перепечатываем с разрешения редакции часть материала «Навигация в информационном пространстве»
<...>Мировые гиганты, такие как OpenAI, Microsoft и DeepSeek, борются за возможность сделать свои продукты максимально мощными и экономичными. Вместе с тем большие языковые модели или LLM (те, что «под капотом» у инструментов ИИ-генерации) имеют и определенные ограничения. Одно из самых обсуждаемых — «необъяснимость» и невозможность проверить достоверность полученной информации. Что становится особенно критично, когда речь заходит о принятии важных решений на базе этой информации, например в сфере безопасности, здоровья и т.д. Одним из способов преодолеть это ограничение стали нейросетевые модели RAG (Retrieval-Augmented Generation).
RAG совмещает преимущества инструментов генерации и поисковых систем. Механизм работы включает два основных шага: 1) извлечение информации (Retrieval) и 2) генерация ответа (Generation). То есть, получив запрос от пользователя, система на базе RAG сначала ищет релевантные документы и фрагменты текста в базе знаний либо в интернете, а затем генерирует осмысленный ответ, опираясь на найденную информацию. И что самое важное — каждый тезис в полученном ответе подтверждается ссылкой на источник данных. Это минимизирует вероятность галлюцинаций (создания выдуманных фактов), чем не редко «грешат» сгенерированные LLM тексты.
Для пользователя это выглядит очень просто. В привычном формате поисковой строки формулируем интересующий нас вопрос. В ответ — получаем складный текст, каждый тезис которого сопровождается кликабельной ссылкой на источник, где можно подробнее ознакомиться с подтверждающей информацией.
Для большей наглядности приведу пример. Сравним три разных подхода к представлению информации в ответ на запрос «Какие профессии будут востребованы в 2050 году?». Первый вариант — традиционная поисковая система (на примере Яндекс), второй — генерация на базе ChatGPT и третий — RAG-модель сервиса Perplexity. Ключевое отличие последнего сразу бросается в глаза: здесь мы получили текст, напоминающий мини-исследование с ссылками, которые подтверждают его достоверность.
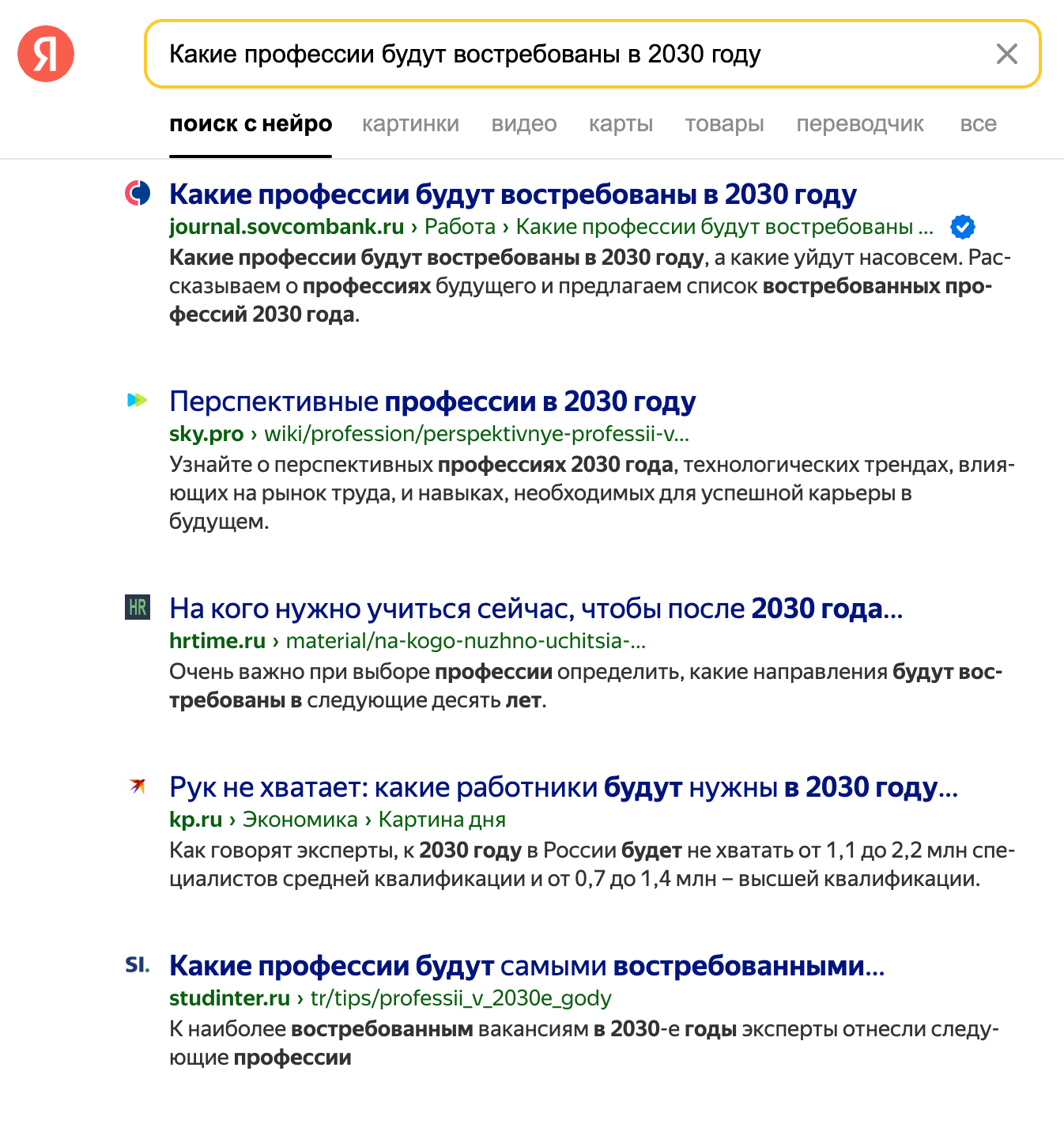{kind=link}
{kind=link}
{kind=link}
За человеком — осмысление результатов и принятие решения
Появление RAG-моделей расширило и трансформировало понимание возможностей поиска в интернете (либо в любой другой базе данных). Преимущества этой архитектуры стимулируют изменения и в альтернативных подходах к обработке информации. Ее элементы уже внедряются и в поисковых системах (например, функция «поиск с нейро» в Яндексе), и в генеративных чатах (например, опция «искать в сети» в GPT-4o). Постепенно все три метода поиска и подачи информации начинают сближаться.
RAG становится незаменимым помощником для умного и гибкого поиска в большом массиве данных. Базой для него может стать как все информационное пространство интернета, так и узкоспециализированная подборка документов, например юридических или медицинских. По этому принципу, к примеру, работает ИИ-ассистент исследователя на базе iFORA, разработанный нашей командой. Используя тщательно отобранную «эталонную» базу источников, он позволяет быстро находить и анализировать актуальные тренды, технологии и прогнозы.
Помогая ориентироваться в обилие окружающей нас информации, ИИ создает прочную основу для анализа и принятия решений. Благодаря этому человек (будь то менеджер, аналитик, врач или руководитель бизнеса) фокусируется на основном — осмыслении результатов и выработке соответствующего им плана действий.