

Ирина Логинова о том, каким может быть пайплайн стратегической big data аналитики
О методологических основах аналитических проектов рассказала завотделом исследований больших данных ИСИЭЗ НИУ ВШЭ Ирина Логинова в колонке для VC.ru.

Концептуальный сдвиг
В передовых странах годами формировалась методология стратегической аналитики. Она помогала принимать решения на высоком уровне, получать рекомендации и действовать. Однако мир стал более связанным, в том числе с точки зрения взаимодействия субъектов хозяйственной деятельности, параллельных процессов, исследований и разработок. Данные теперь отражают намного более комплексные процессы, что тянет за собой усложнение самой методологии и очевидные проблемы с ее воспроизводимостью.
Традиционные подходы, ядром которых является ручная экспертно-аналитическая работа, обладают существенными ограничениями: от скорости обработки информации и возможных ошибок до влияния специализации аналитика и его субъективных решений на результаты. В последнем случае это может быть поверхностное сканирование материалов и изложение выводов без должной детализации, лоббирование собственных или чужих интересов, несовершенное владение иностранными языками и прочие ограничения.
На помощь приходит автоматизированный анализ больших данных, который принципиально отличается от традиционных подходов. Здесь основным поставщиком аналитических продуктов — с ограничениями — является не человек, а интеллектуальная система.
Такой подход гарантирует прозрачность анализа, воспроизводимость результатов, низкий риск ошибок и предвзятости. Анализ больших данных позволяет выявить неявные закономерности, которые могли быть недоступны аналитику при чтении отдельных текстов. Конечно же, автоматизация позволяет охватить десятки миллионов документов, контролировать обновление библиотеки данных и так далее.
Дискуссия не утихает
Сегодня можно заметить лозунговую дата-ориентированность у огромного количества организаций, хотя еще прошлом году в Gartner подчеркнули, что большие данные устарели: существенный объем собираемых компаниями данных бесполезен, а аналитики вынуждены разгребать «мусорные» данные, польза которых для принятия решений остается под вопросом. В качестве перспективных в Gartner выделяют малые, генерируемые, мета- и синтетические данные.

Сами по себе данные, конечно же, не приводят к решениям. Дело в том, что сегодня анализ больших данных во многом ориентирован на аналитиков, а не на ЛПР. Последним сложно действовать только на основе данных, поэтому дата-команды должны предложить еще и аналитические фреймворки, содержащие опции и развилки. Чтобы определять такие возможности, нужно задавать конкретные и ограниченные вопросы в ходе анализа данных.
Поэтому запрос на лимитированные, чистые и обогащенные данные следует рассматривать с точки зрения проектирования гибридных инструментов и методов, основанных как на процедурах автоматизированной обработки, так и на экспертных методах для верификации результатов анализа. Это необходимо, чтобы добраться до формирования стратегических приоритетов.
Классика жанра
Стратегические приоритеты компаний не формируются напрямую из направлений деятельности, например, из перечня продуктовых портфелей. Хотя они могут выражаться в бизнес-категориях — рынках и сегментах, где планирует масштабирование компания, технологиях. Если обратиться к классическому менеджменту и маркетингу, можно выделить несколько моделей, определяющих процедуру формирования стратегических приоритетов.
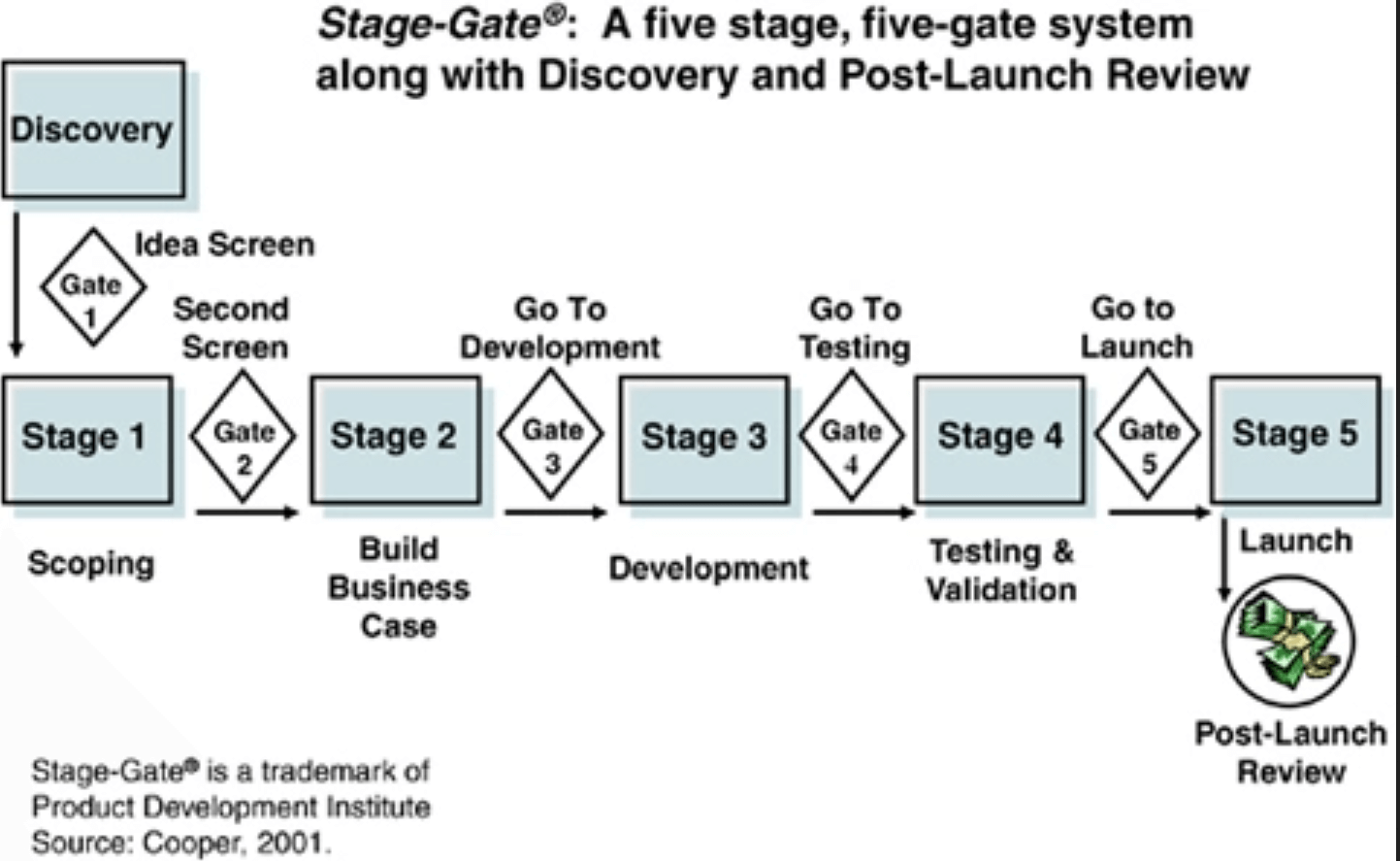
1986 — «ворота» инновационного процесса Р. Купера
В рамках подхода Stage-Gate инновационный процесс рассматривается как частный пример любого типового управленческого бизнес-процесса. Последний делят на несколько этапов, разделенных «воротами контроля качества». Для ворот регламентирован набор результатов и критериев качества, которым продукт, находясь на данном этапе, должен соответствовать, прежде чем перейти на следующую стадию разработки.
Результатами будут являться решения — например, «запуск» или «приостановка», а также утверждение действий для следующего этапа. Обычно процесс состоит их четырех⎯семи этапов и ворот, в зависимости от задач компании. По мере продвижения генерируется все большие объемы аналитики вокруг продукта, что сокращает риски запуска.
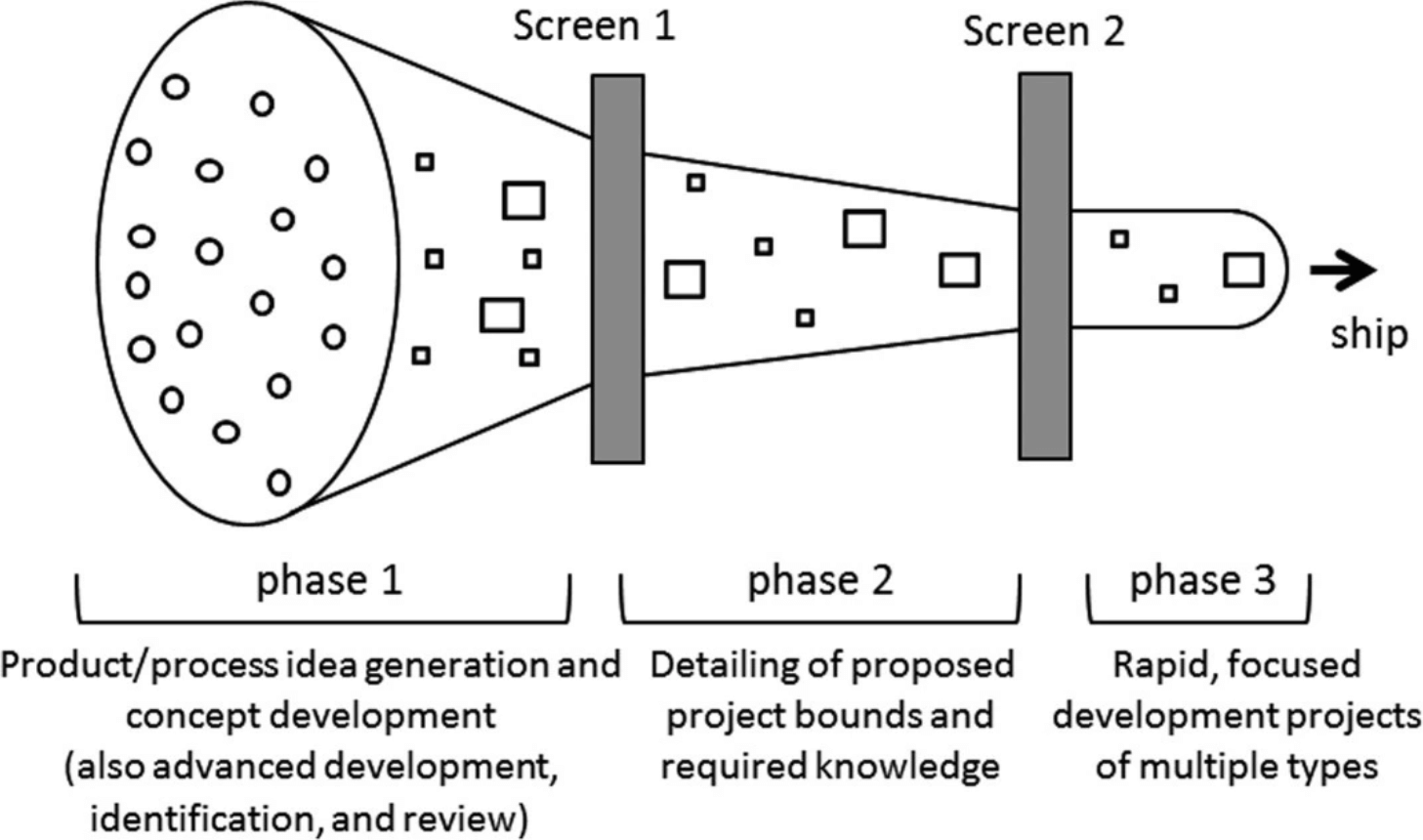
1992 — модель инновационного процесса Уилрайта-Кларка
Модель представляет идею воронки, которая направлена на выбор проектов. Хотя эта идея отражена не так явно, как в Stage-Gate, воронка графически и явно демонстрирует избирательность в методологии.
Графическая модель транслирует, что лишь некоторые из нескольких идей получат место в портфеле организации. Аналогия с воронкой получила широкое признание и стала прототипом для многих последующих аналитических моделей в инновационном менеджменте.
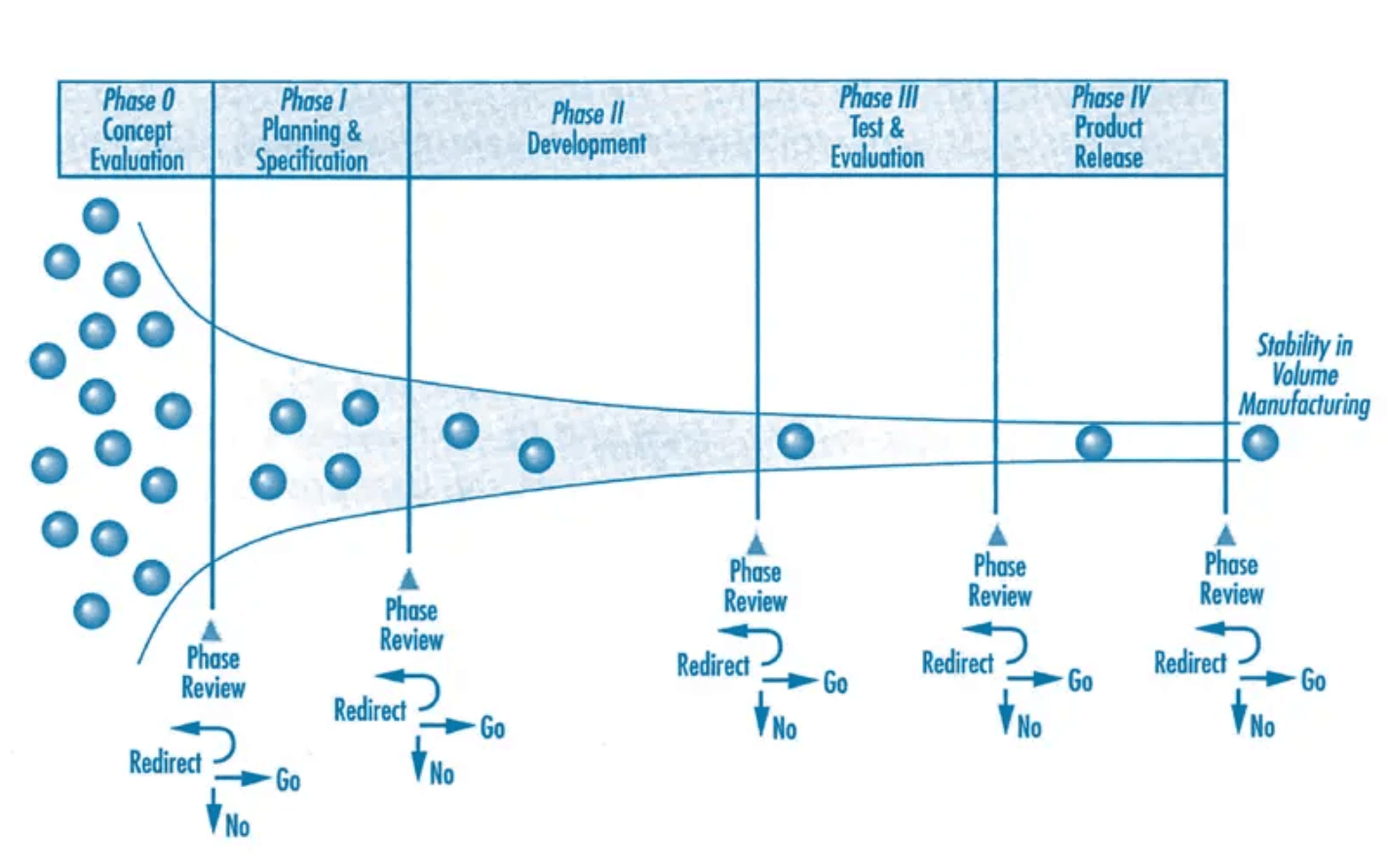
1992 — воронка разработки нового продукта PACE М. МакГрата
Первый этап PACE описывает оценку концепций нового продукта на основе синтеза продуктовых идей. Подобно Куперу, МакГрат отражает необходимость периодического процесса — управленческой или поэтапной проверки. В остальном методология эквивалентна Stage Gate.
Еще одна особенность процесса МакГрата заключается в том, что он включает в воронку экономическое обоснование в качестве основного этапа до формальной разработки. Как и в подходе Купера, внимание автора сосредоточено на портфеле реализуемых проектов, которые необходимо периодически проверять. Мало информации о том, откуда берутся сами продуктовые идеи, но они предшествуют входу.
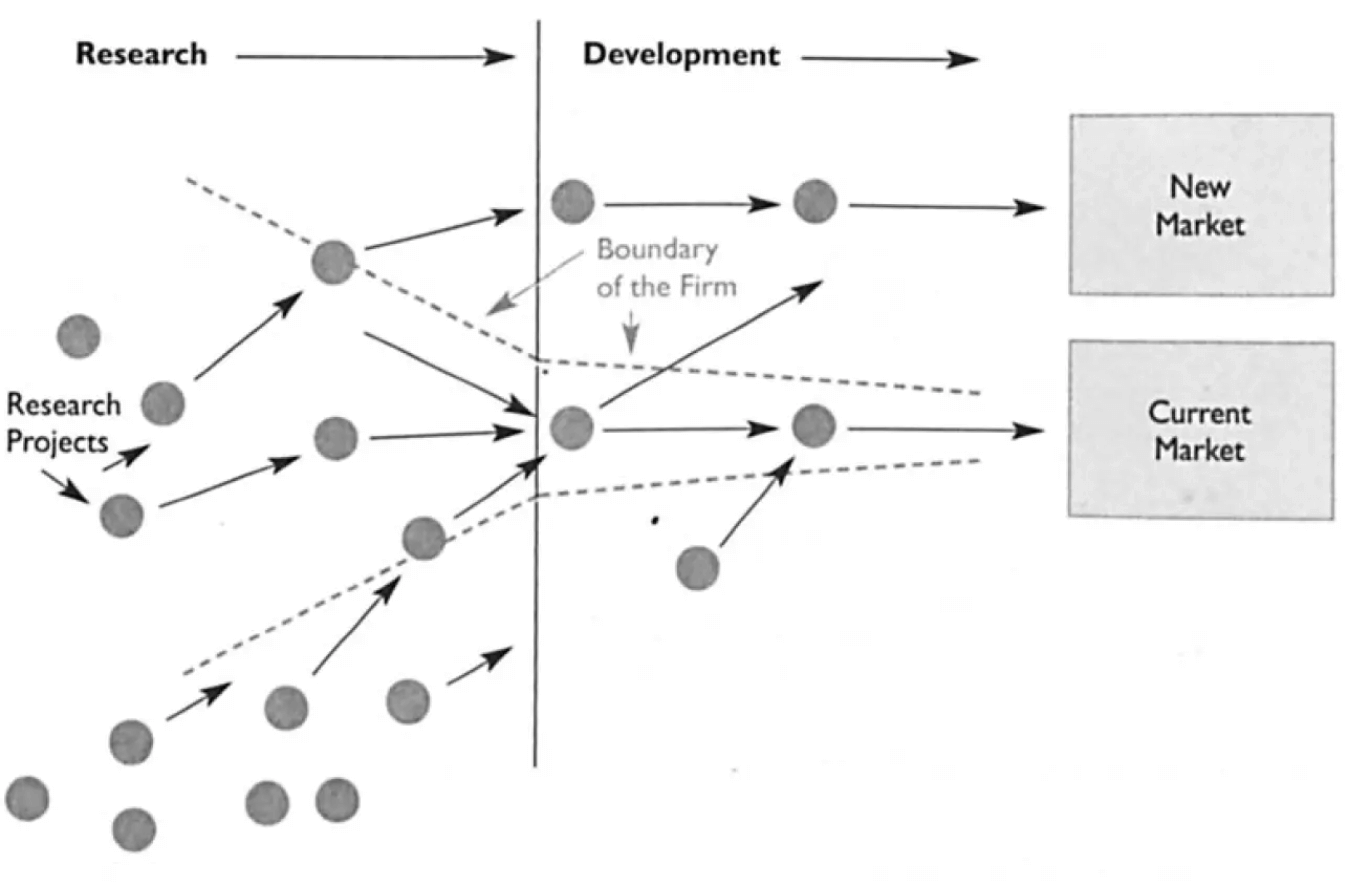
2003 — модель открытых инноваций Г. Чесбро
Модель открытых инноваций направлена на объединение внутреннего и внешнего использования инноваций и технологий, чтобы обеспечить более эффективный поток идей на стадию исследований по сравнению с моделью закрытых инноваций. Творческие идеи черпают как изнутри, так и за пределами компании. Модель предполагает, что компания должна участвовать в фундаментальных исследованиях.
2005 — воронка MIT CIPD
Модель похожа на подход, предложенный МакГратом. Это — буквальная воронка из четырех этапов, по которой параллельно проходят несколько проектов. Вход в воронку и явный запуск отсутствует, а название звучит абстрактно — идентификация возможностей и генерация идей.
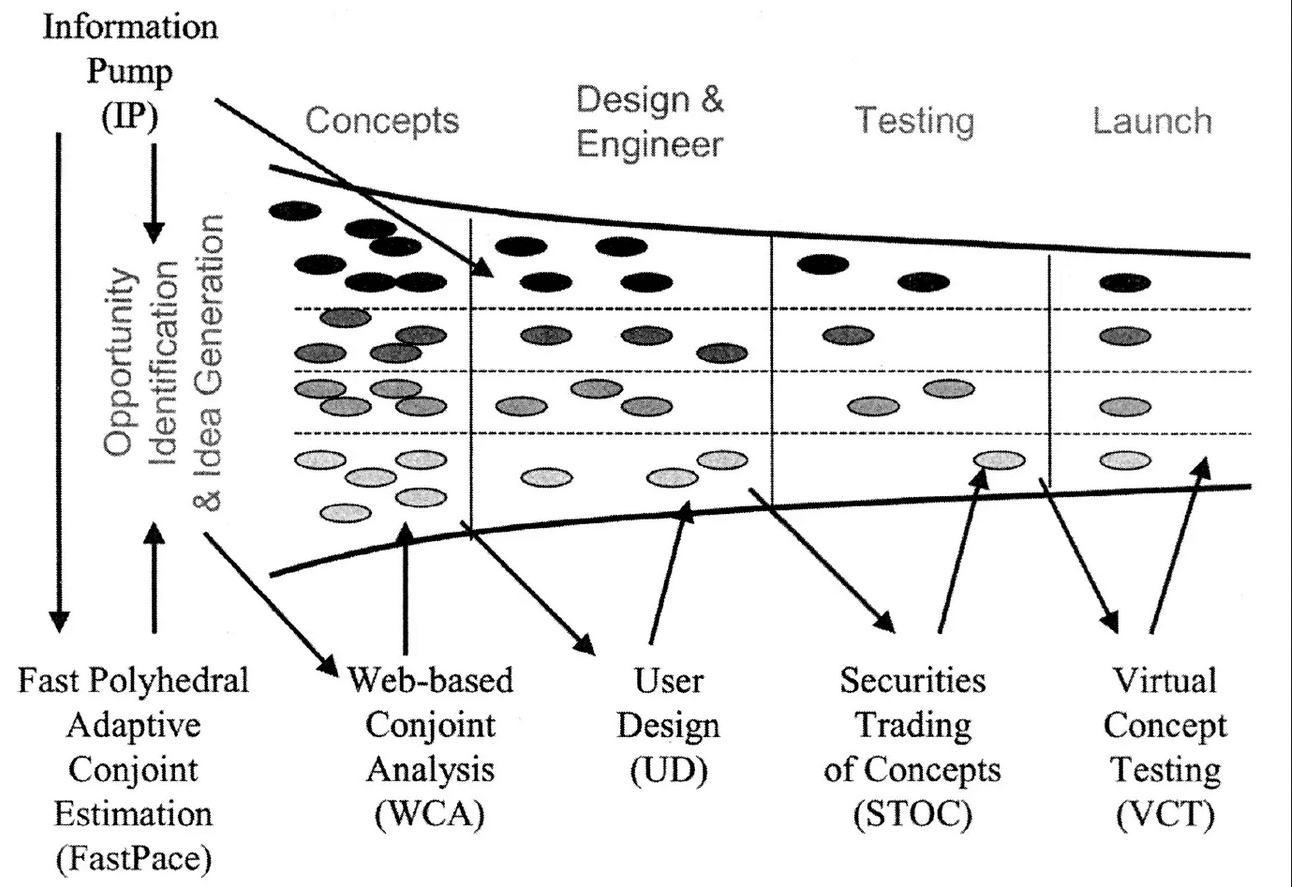
2011 — «новая» воронка развития продукта Gerry Katz
Модель не демонстрирует радикально инновационных подходов, за исключением того, что на четырех из пяти этапов мы видим специфические задачи для реализации. С точки зрения смыслов отражены классические этапы воронки: сканирование внешней среды, оценка потребности рынка и постановка цели с разработкой требований, формирование и оценка концепции, разработка продукта и прототипирование, плюс — позиционирование и запуск.
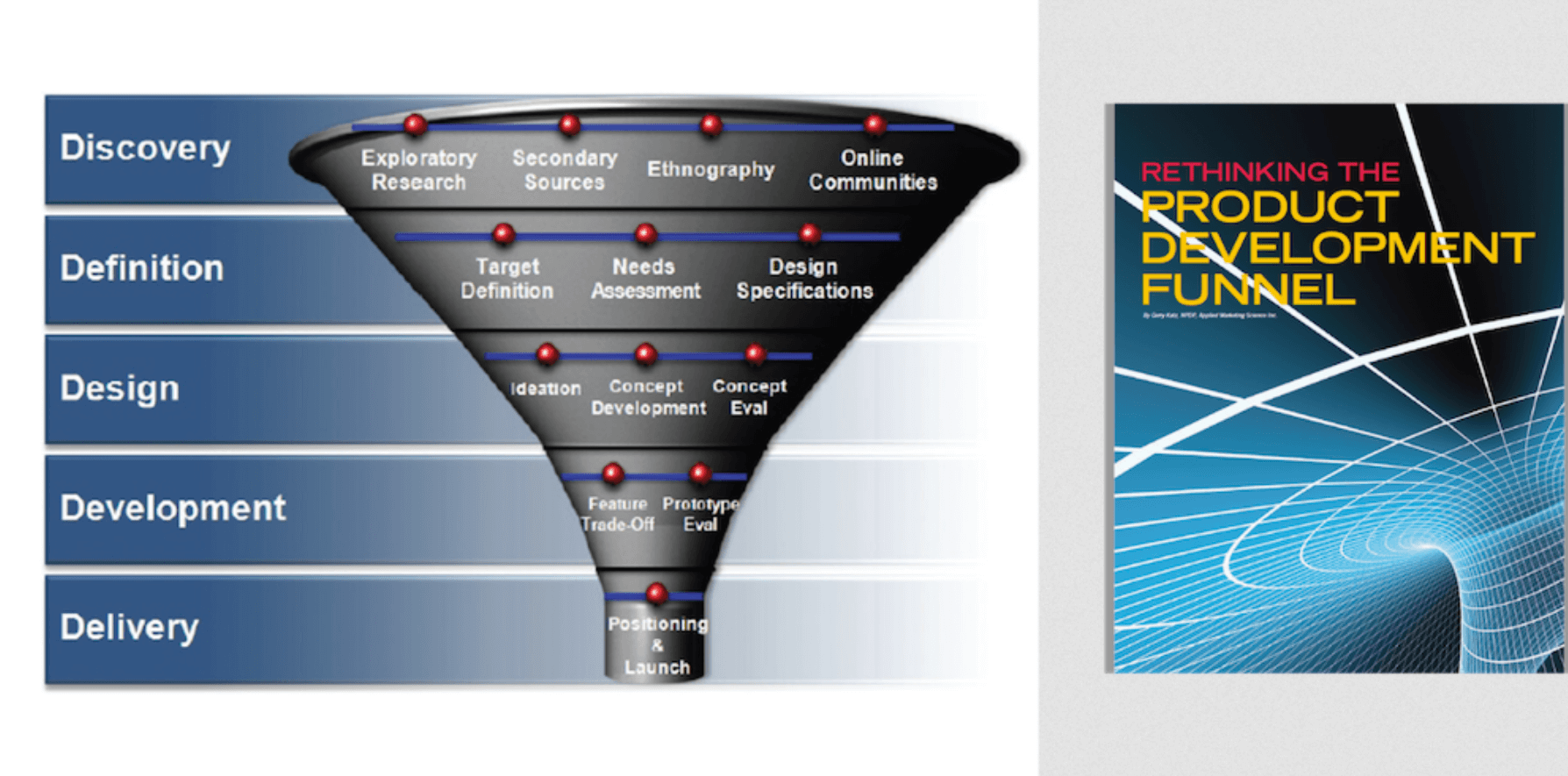
Что объединяет описанные подходы. Преимущественно — экспертный метод реализации. Это — в первую очередь — вдумчивая работа нарративных экспертов-аналитиков, связанная с кабинетными поисковыми исследованиями, интервью, фокус-группами. Такие подходы на выходе дадут чистый результат, но издержки на реализацию возрастают кратно, и не до конца понятно, как быть с первым креативным шагом. Получается, что преимущества и недостатки больших и малых данных буквально отзеркаливают друг друга. Возможен ли баланс?
Нарративы и воронка гипотез
Мы выделяем принципиальную роль текстовых данных в задачах конкурентной разведки и стратегической аналитики в широком понимании дисциплины. Количественные данные, как правило, отражают текущие процессы, их анализ не позволяет сформировать нелинейные прогнозы. Текст же содержит идеи, мнения и нарративы, касающиеся долгосрочных перспектив, гипотез о сценариях развития общества. Несколько лет назад мы в ИСИЭЗ НИУ ВШЭ начали разрабатывать интеллектуальную систему анализа больших текстовых данных iFORA, призванную помогать эксперту в его работе, автоматизировать анализ миллионов документов и побороть субъективность. Однако одной системой дело не ограничивается: как мы отметили выше, необходим гибрид ИТ и методологии.
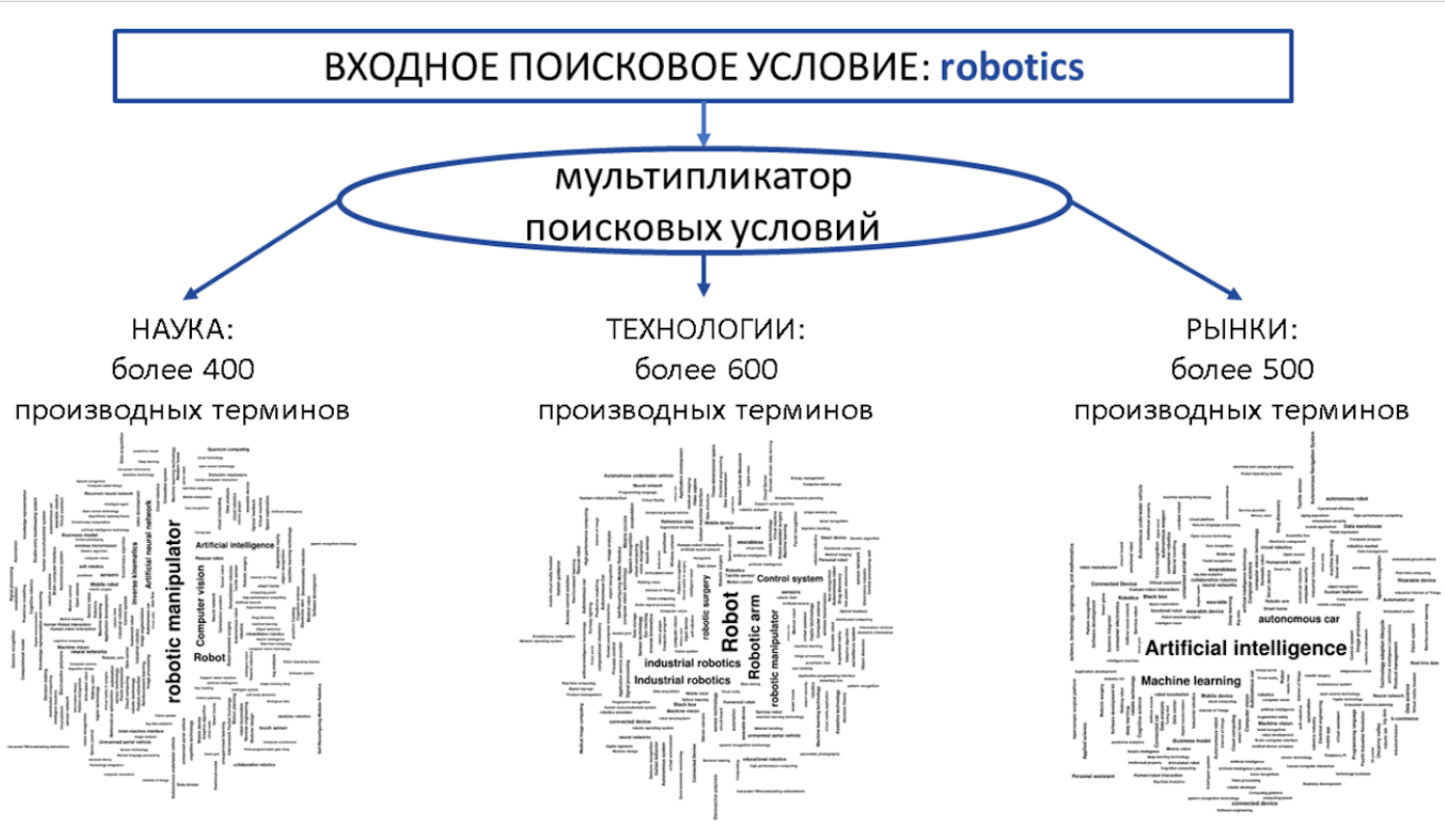
Нарративы стратегической аналитики зачастую сводят к перечням: какие технологии развивать, какие направления науки отслеживать, на какие коллективы специалистов обращать внимание. Такие нарративы выражают в терминах, утверждениях и иногда документах, а сами — например, термины — в процессе аналитики называют гипотезами или кандидатными терминами. Такой статус подчеркивает, что решение по тому или иному термину в ходе анализа не принято.
Гипотезы строят по любым видам объектов, представляющим интерес для заказчика: продукты, рынки, технологии, тренды, центры компетенций, персоналии. Процесс работы с гипотезами лежит в основе новой сквозной воспроизводимой методологии по выявлению приоритетных направлений развития (продуктовых, технологических, научных) для заказчика с учетом его стратегических векторов развития.
Воронка иллюстрирует принцип последовательного сокращения количества исследуемых гипотез в результате использования различных методов исследования этих гипотез. Гипотеза внутри воронки обладает жизненным циклом, проходя путь от первичной идеи до валидированной и верифицированной. Воронка состоит из нескольких уровней или шагов, этапов и в зависимости от сложности поставленной задачи, таких уровней может быть в среднем от трех до пяти. Каждому этапу соответствует специальный метод и конкретный результат.
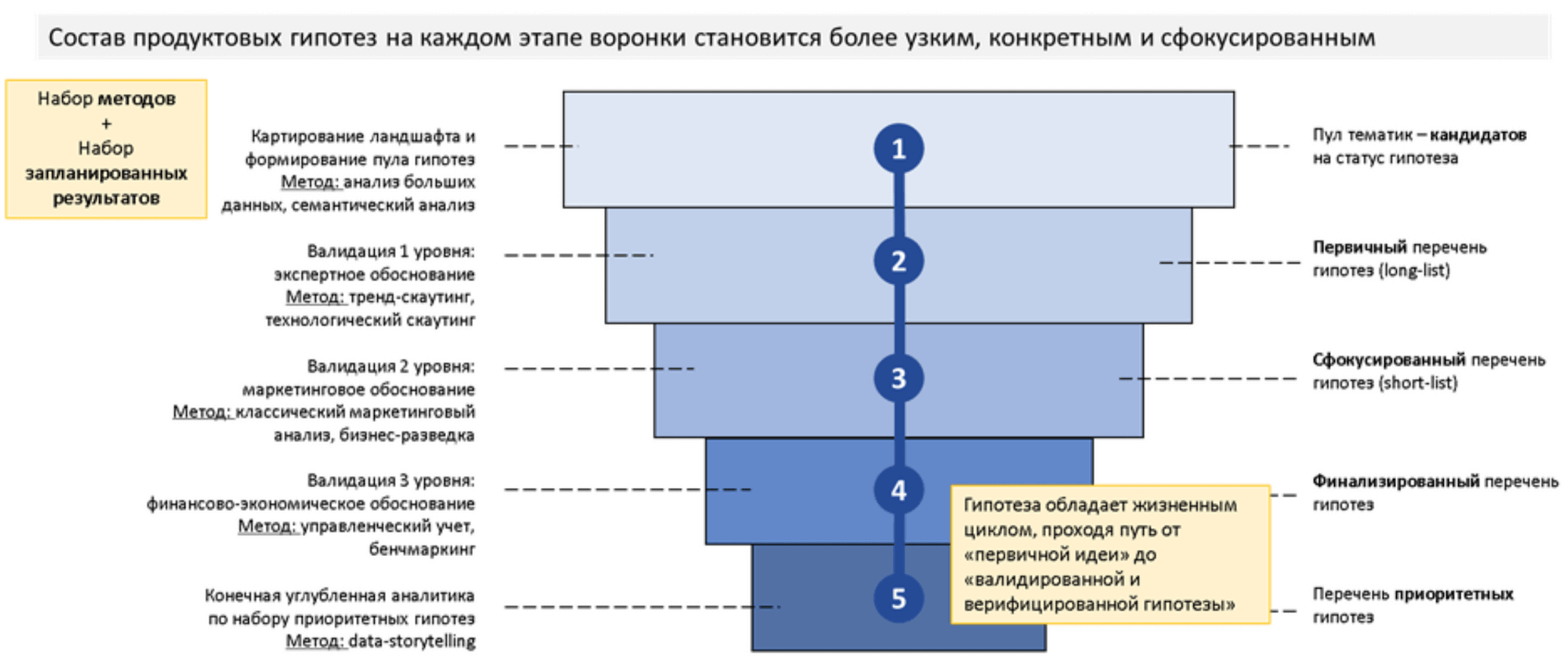
Воронка гипотез — это в то же время воронка методов и воронка регламентированных результатов. На вход подают неструктурированные перечни гипотез, полученные из больших текстовых данных, которые имеют различный уровень детализации (как общие направления, так и узкие); не систематизированы (нет иерархии); не обладают признаками, необходимыми для ранжирования и сравнения отдельных гипотез.
Откуда вообще берутся термины и гипотезы — тема отдельной статьи. Здесь нужно подробнее углубляться в саму систему, принципы ее работы, базу данных, NLP-алгоритмы и прочее. Ограничимся комментарием о том, что такие первичные перечни гипотез формируются в автоматическом режиме посредством обращения к системе и ее базе данных, состоящей из сотен млн разных типов документов (научные публикации, патенты, новостные сообщения и так далее) с помощью поискового запроса, который описывает стратегический вектор заказчика. В ядре воронке работают люди, предметные эксперты, там происходит многостадийная экспертная валидация гипотез. На выходе аналитик получает полноценные форматы: аналитические паспорта, дайджесты, концепции бизнес-проектов.
Что дальше
Такой методический подход — иллюстрация к системе поэтапного движения из точки А (вход воронки) в точку Б (результат прохождения по воронке). Точкой А являются неструктурированные данные, которые мы можем получить из семантики. Они обладают своей спецификой, что затрудняет их быстрое практическое использование. Точкой Б является тот результат, который для себя полезным видит заказчик. Это могут быть в том числе и данные, но такие данные и в таком виде, чтобы заказчик мог их использовать в целях принятия решений (чистые, структурированные, образованные в иерархии и таксономии).
Так, данные можно рейтинговать, ранжировать, агрегировать и строить такие аналитические срезы, которые будут отвечать поставленным задачам. Это — путь от сырых данных к общепринятым в управленческой науке понятиям как знание и инсайт, фигурирующих в классических моделях вроде DIKW и адаптированных к SDIKI. Кстати, накапливаемые результаты (чистые данные) — это еще и база для совершенствования языковых моделей, сокращения пути по воронке.
В целом мы говорим о движении в сторону гибридной и воспроизводимой методологии, использующей возможности интеллектуальных систем анализа больших данных. Такой подход позволяет проверять большое количество гипотез, гибко управлять шагами, итеративно двигаться к результату, отбирать варианты по комплексу объективных качественных и количественных критериев, снизить риски человеческого фактора и привлекать к участию в аналитическом процессе топ-менеджмент заказчика.
Материал впервые опубликован в блоге на VC.ru, который ведет Дмитрий Кабанов, ведущий эксперт Центра исследований цифровой экономики ИСИЭЗ НИУ ВШЭ